- 版权声明:
本文原文 为 keys961 的博客文章, 该存储库 已在 GitHub上采用 MIT 协议开源。
由于该博客文章对于我学习 ZooKeeper 带来了很大帮助和启发,故在此基础上加以完善和补充部分内容。
简介
分布式场景需要协调服务:如 Leader 选举、分布式锁等。而 ZooKeeper 是一个协调内核,提供API为上层实现自己的协调原语。
ZooKeeper API 是无等待的(非阻塞),且与文件系统非常相似。
它提供顺序保证:
- 提供线性化写
- 使用Leader原子广播协议Zab保证(保证多副本强一致,而多副本提供了高可用和读高性能)
- 因此,它适用于写少读多的场景,专门对读进行优化(多副本下,读只在本地进行,不需广播)
- 保证所有操作先进先出的客户端顺序
- 使用单管道架构实现ZooKeeper,让客户端可异步提交操作
它还提供:
- watch机制(监听)
- 让客户端可监视到更新(从而简化客户端缓存实现)
本文主要涉及:
- 协调内核:ZooKeeper本身实现,提供一个无等待松散一致性的协调服务
- 协调实例:如何使用ZooKeeper构建高级协调原语
- 协调经验:使用ZooKeeper的经验
ZooKeeper服务
术语:
- 客户端:使用ZooKeeper服务的客户端
- 服务端:ZooKeeper本身服务
znode:ZooKeeper内存数据节点,它以层次形式组织,形成数据树- 会话:客户端连接到ZooKeeper时,建立会话,并获取会话句柄
服务总览
znode
ZooKeeper使用znode表示数据,且以树形形式表示(类似文件系统)。
znode分为2类:
- 普通:客户端需要显式创建/删除这类节点
- 临时:客户端创建这类节点后,当其会话结束后,节点自动删除
创建节点时,可指定sequential标志,可让节点创建的序列号单调递增,且序列号的值会添加到节点名称之后。
ZooKeeper实现watches,客户端可监听某个znode,然后通过回调进行通知。
数据模型
ZooKeeper使用简化的API提供类似文件系统的数据模型,只能一次读取/写入所有数据或者带有层次的键值表(树形结构为键)。
znode不存储通用数据,而主要映射客户端应用的抽象(主要是协调用的元数据)
会话
客户端连接到ZooKeeper时初始化一个会话。它有超时时间,到期后则认为客户端已关闭,会话终止。
会话中,客户端可持续观察服务端状态变化。
此外会话让客户端在ZooKeeper服务器集合中透明地从一个服务器移动到另一个服务器。
客户端API
-
create(path, data, flags):创建path的znode节点,保存data,返回新的znode的名字。flag用于指明znode类型,也可指明是否使用顺序标志。 -
delete(path, version):删除path的znode节点,并且版本号满足version。 -
exists(path, watch):返回path的znode是否存在。watch可允许客户端在该节点上应用watch。 -
getData(path, watch):获取path的znode的值,watch和exists()一样,除非znode不存在。 -
setData(path, data, version):向path下的znode写入data,节点版本需要匹配version。 -
getChildren(path, watch):返回path子节点的所有名字。 -
sync(path):操作开始时,等待所有的更新都发送到客户端所连接的服务器,path是保留参数,没有用。
方法都有同步和异步的实现,对于异步,可保证回调的顺序和客户端调用的顺序一样。
ZooKeeper的保证
顺序保证:
- 线性化写:更新操作都是线性化的,且遵守优先级
- FIFO客户端顺序:一个客户端的所有请求,都按照客户端发送顺序执行
这里的线性化是异步线性化,和传统的线性化不同,客户端可以有多个未完成的操作,因此需要保证所有操作的执行是FIFO的顺序,以保证更新的线性化。
由于ZooKeeper只对更新异步线性化,因此,ZooKeeper可以在每个副本上各自处理读请求,这种情况下,读不是线性化的,要保证线性化,需要调用sync(),以看到最新的数据。(写则必须通过Master,通过Zab协议广播)
活性和持久化保证:
- 大部分节点存活,则服务可用
- 若服务对于某个更新请求成功响应,只要服务(quorum数量的节点)能最终恢复,变更就能在任何数量的故障中持久化
原语示例
配置管理
将配置信息保存在znode中。进程读取znode的值,并设置watch为真。
当配置变化后,进程会被通知,重新读取后,再设置watch为真。
信息汇合
有时候,分布式系统的最终配置不能提前知道。
因此启动时,主进程可创建一个znode,存储动态的配置信息(如动态调度的IP和端口),工作进程读取这个znode,并设置watch为真,若节点没值,则等待。znode可设置成临时节点,工作进程可通过监听来判断自己是否需要清理。
群组关系
通过临时节点以及树形结构,可以动态管理群组成员的关系,比如服务发现。
锁
ZooKeeper用于可实现分布式锁服务。
简单互斥锁
一个简单的锁可通过创建znode节点完成:
- 上锁:创建临时
znode尝试获得锁,若创建成功则获取锁,否则监听已有的znode - 解锁:删除
znode释放锁(此时通知等待的客户端,以获取锁)
上述锁会有2个缺点:
- 节点多时,造成羊群效应(过多客户端监听同一个
znode,通知时造成流量尖峰,导致网络阻塞) - 只实现了互斥锁
无羊群效应的互斥锁
- 上锁:
|
|
上述监听,一个znode上监听的客户端数量大大减少,通知时造成的峰值可以避免。
-
解锁:
只需删除创建的节点即可。
|
|
读写锁
- 写锁
|
|
和之前的互斥锁一样。
- 读锁
|
|
双屏障
让客户端在计算的开始和结束同步,
语义:
- 当有足够多的进程进入屏障后,才开始执行任务;
- 当所有的进程都执行完各自的任务后,屏障才撤销。
进入屏障:
- 客户端监听
/barrier/ready结点, 通过判断该结点是否存在来决定是否启动任务 - 每个任务进程进入屏障时创建一个临时节点
/barrier/process/${process_id},然后检查进入屏障的结点数是否达到指定的值- 如果达到了指定的值,就创建一个
/barrier/ready结点 - 否则等待客户端收到
/barrier/ready创建的通知,以启动任务
- 如果达到了指定的值,就创建一个
离开屏障:
- 客户端监听
/barrier/process节点,若子节点为空,离开屏障 - 任务进程完成后,删除
/barrier/process/${process_id}节点
ZooKeeper应用
-
Yahoo!的爬虫服务 Fetching Service(FS)使用ZooKeeper来管理配置元数据和选举主节点。
-
Katta(分布式索引)使用ZooKeeper跟踪组成员状态、并进行领导者选举、配置管理。
-
Yahoo! Message Broker(YMB)(分布式发布-订阅系统)应用了ZooKeeper。
ZooKeeper实现
ZooKeeper的组件图如下:
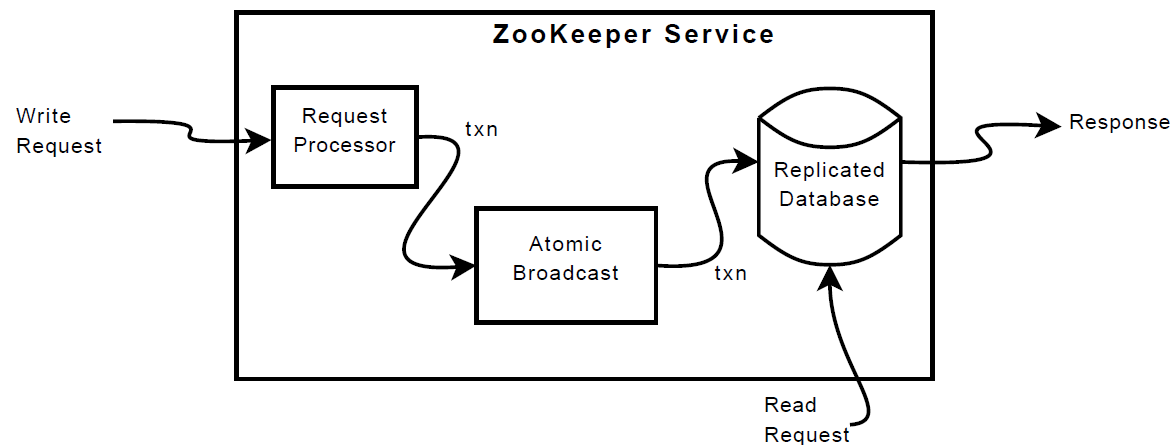
副本数据库是包含整颗树的内存数据库,最大为 1MB(可以通过配置文件修改),为了恢复,会使用 WAL,保留一个已提交操作的 replay log(在 ZooKeeper 中是一个写前日志),并周期性生成快照。
数据库可恢复操作分为备份和 WAL 两种:
备份(Rollback Journal):需要对一条数据做更新操作前,先将这条数据备份在一个地方,然后去更新,如果更新失败,可以从备份数据中回写回来。这样就可以保证事务的回滚,就可以保证数据操作的原子性了。其实 SQLite 引入 WAL 之前就是通过这种方式来实现原子事务,机制的原理是:在修改数据库文件中的数据之前,先将修改所在分页中的数据备份在另外一个地方,然后才将修改写入到数据库文件中;如果事务失败,则将备份数据拷贝回来,撤销修改;如果事务成功,则删除备份数据,提交修改。
WAL:修改并不直接写入到数据库文件中,而是写入到另外一个称为 WAL 的文件中;如果事务失败,WAL 中的记录会被忽略,撤销修改;如果事务成功,它将在随后的某个时间被写回到数据库文件中,提交修改。
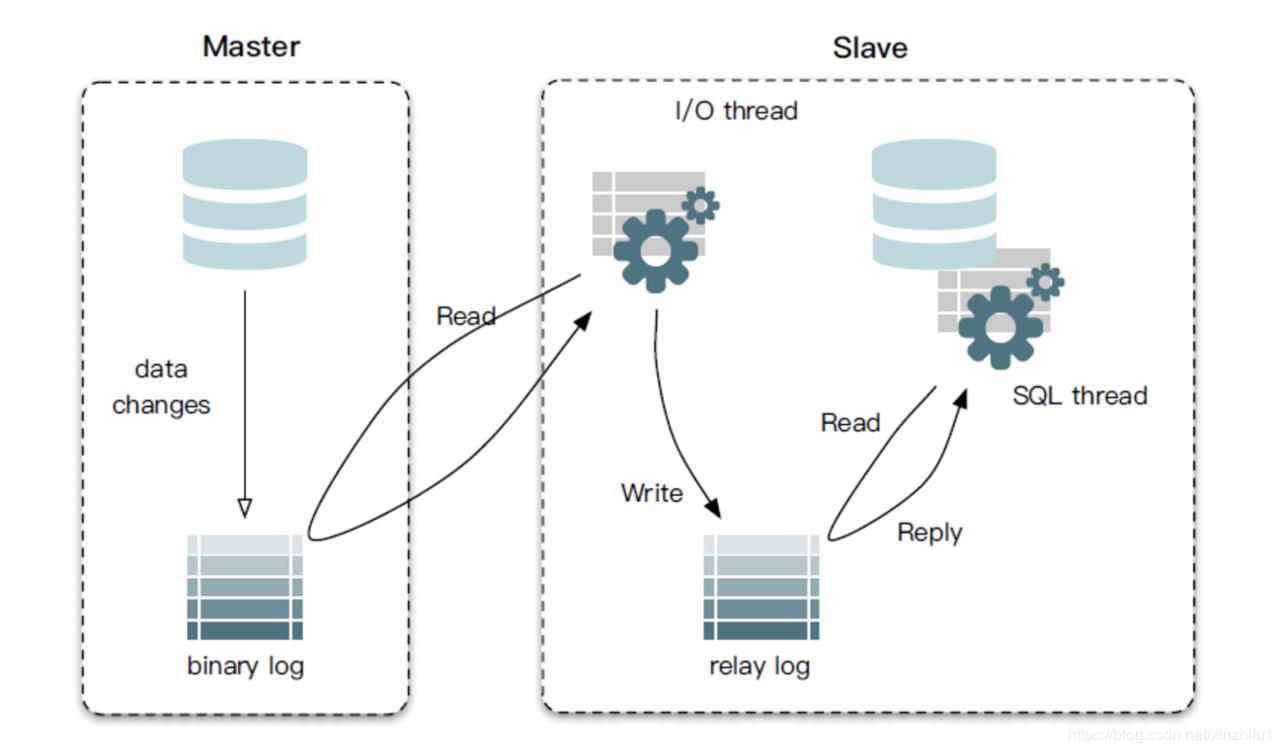
replay log:参考下图(MySQL 的 replay log 结构),它是一个中介临时的日志文件,用于存储从 Leader 节点同步过来的日志内容,它里面的内容和 Leader 节点的日志里面的内容是一致的。然后 Followers 从节点从这个 relay log 日志文件中读取数据应用到数据库中,来实现数据的主从复制。
读取请求可落到所有的副本上,写入请求被路由(转发)到 Leader 上(然后通过Zab广播同步)。
请求处理器
为了让事务幂等,Leader收到写请求,会计算得到写入后的状态,并将请求转化成一个包含这个新状态的事务条目。
幂等:多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致。
如一个写请求setData,那么:
-
请求中的版本号与被更新的znode的未来版本号相匹配(成功时),生成
setDataTXN,包含新数据,新版本号以及更新时间戳 -
失败时(例如版本号不匹配或要更新的znode不存在),生成
errorTXN
原子广播
所有的写请求会路由到 Leader,然后由 Leader 广播到 Follower 上(通过 Zab 协议)。
Zab 默认使用多数服从原则,即对于$2f+1$个节点,可容忍$f$个故障。
为了实现高吞吐量,ZooKeeper尽量保持请求处理管道是满的。由于当前状态的改变依赖于之前的改变,Zab提供了比通常的原子广播更强的顺序保证,即:
- 保证Leader的变更广播按照发送顺序发送
- 之前的Leader的所有变更会在新Leader广播之前传到新Leader上
实现上:
-
使用TCP协议,保证了传输可靠(完整性、顺序等)以及高性能
-
使用Zab选出的Leader作为ZooKeeper的Leader
-
使用WAL来记录Zab的广播。
-
Zab广播消息实现exactly-once,由于事务是幂等的,且消息按顺序发送,则Zab重新广播(如恢复时)也是可以接受的
实际上,ZooKeeper要求Zab重新发送从上一个快照开始时已经传送过的消息。
副本数据库
ZooKeeper使用多副本提高可用性。当节点宕机,为加快恢复速度,使用快照以加速恢复,并只重新发送从该快照开始时的消息。
Fuzzy Snapshot:
ZooKeeper记录快照时,不锁状态,而对树进行深搜,扫描时将znode状态和元数据写入磁盘。尽管快照会包含状态变化的子集,但是由于幂等事务和顺序写入,变更可应用多次,满足exactly-once。
C/S交互
写请求
-
将更新相关的通知发出去,并关闭对应的watch会话。
-
写请求不会和任何请求并发进行(包括和读并发进行),严格按照顺序处理,这保证了通知的严格一致
-
通知是在各个副本的本地进行,而并非全在Leader
读请求
-
请求在各个副本的本地执行(无读盘以及协商,性能很高)
-
每个读请求被赋上
zxid,它等于最后一个服务端见到的事务,zxid定义了读请求相对于写请求的部分顺序。
Sync
普通读请求可能会读到旧数据,通过sync()以读到最新的数据
-
异步执行,Leader挂起写入,将数据同步到Follower后,再继续下去
-
客户端只需读取后立即调用
sync(),客户端FIFO特性以及sync()的全局特性,保证调用sync()之前的所有变更都会被读取看到
其它
-
服务端响应请求时包含
zxid,心跳消息需要包含最后一个zxid。 -
客户端连接到新的服务器,新服务器通过检查客户端最后一个
zxid和自己的zxid: : 若客户端的zxid大,在服务器赶上之前,客户端与服务器不会建立会话,即客户端保证它找到的服务器包含更新的视图。这可以保证集群的持久性。 -
故障探测使用超时机制:
-
若会话超时期间,没有其他服务器从客户端会话收到任何内容,则Leader确定Client存在故障,会话终止。
-
如果客户端向服务器请求比较频繁,则无需发送心跳消息。否则客户端低频率发送心跳,若不能通信,则会重新连到其它服务器以重建会话。
-
为了防止会话超时,ZooKeeper客户端库在会话闲置s/3毫秒后发送心跳,如果2s/3毫秒内没有服务器的消息,则切换到一个新的服务器,其中s是会话超时,单位为毫秒。